
Deep Learning with Differential Privacy 阅读记录
Deep Learning with Differential Privacy 阅读记录
Created: Mar 23, 2021 2:27 PM
Created By: JK H
Last Edited By: JK H
Last Edited Time: Apr 1, 2021 12:58 AM
Overview
Differential Privacy 概念
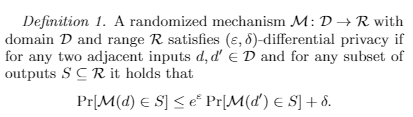
D:定义域(input) R:值域(output) S是R的一个子集
M是 D→R 的映射
d和d’是一组临近数据,掌握足够多先验知识后,可以判断原输入到底是d还是d’
满足差分隐私即无法区分d和d’
我们引入噪声使得M(d)和M(d’)分布足够接近
定义,对于任意输出 S ⊆ R,满足
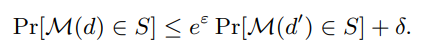
- 项是确保了隐私泄露的概率有一个数学的上界
- 原本的定义中不含δ项, (ε, δ)-DP 在 ε-DP 的基础上允许了一定概率的错误
Properties
- composability enables modular design of mechanisms: if allthe components of a mechanism are differentially private,then so is their composition. (可结合性)
- group privacy implies graceful degradation of privacy guarantees if datasets contain cor-related inputs. (隐私保证的降级)
- robustness to auxiliary information means that privacy guarantees are not affected by any side information available to the adversary. (隐私保证不受辅助信息影响)
Gaussian noise mechanism(高斯机制)
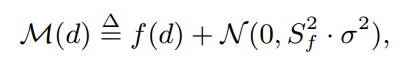
噪声满足高斯分布 with mean 0 and standard deviation
satisfies (ε,δ) - differential privacy if
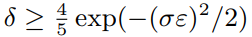
另见:Laplace机制
Implements: steps
- approximating the functionality by a sequential composition (顺序组成)of bounded-sensitivity(有界灵敏度) functions;
- choosing parameters of additive noise;
- performing privacy analysis of the resulting mechanism.
设计一种差分私有加噪音机制的步骤:
i)通过有界灵敏度的顺序组成来逼近函数
ii)选择加噪参数
iii)对生成机制进行隐私分析
Algorithm
SGD算法
这里选择了更精细的方法来控制训练数据的影响,平衡隐私保护和可用性,防止保守估计的噪声破坏模型的有效性
- minimizing the empirical loss function
- compute the gradient for a random subset of examples
- clip the norm of each gradient
- compute the average
- add noise in order to protect privacy
- take a step in the opposite direction of this average noisy gradient
- compute the privacy loss of the mechanism based on the information maintained by the privacy accountant

Norm clipping
the gradient vector g is replaced by
Per-layer and time-dependent parameters
setting different clipping thresholds C and noise scales σ for different layers.
lots
通过计算一组例子的梯度并取平均估算L的梯度。这个平均值提供了一个无偏差的估计值,它的变化随着数据量的增加迅速减少。称这个组合为lot,与通常的计算组合batch区别开
- set the batch size much smaller than the lot size L
- group several batches into a lot for adding noise
- an epoch consists of N/L lots
Privacy accounting
compute the privacy cost at each access to the training data, and accumulates this cost as the training progresses.
moments accountant
对于高斯噪声而言,若我们选择 Algo 1 中的
那么根据标准参数,每一步对于此 lot 都满足 (ε,δ) - differentially private
Since the lot itself is a random sample from the database, the privacy amplification theorem implies that each step is (qε,qδ) - differentially private with respect to the full database where q=L/N is the sampling ratio per lot.
Prove that Algorithm 1 is () - differentially private for appropriately chosen settings of the noise scale and the clipping threshold
Our bound is tighter in two ways:
- a factor in the ε part
- a Tq factor in the δ part
Expect δ to be small and T >> 1/q (i.e., each example is examined multiple times)
Theorem1.
There exist constants c1 and c2 so that given the sampling probability q = L/N and the number of steps T, for any , Algorithm 1 is (ε,δ) - differentially private for any δ > 0 if we choose
使用强组合理论的话会多出一个 的因子,并且 ε 可能会大得多
Details
隐私损失定义
For neighboring databases d, d′ ∈ Dn, a mechanism M, auxiliary input aux, and an outcome o∈R, define the privacy loss at o as
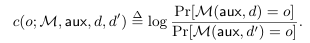
adaptive composition
让之前机制的输出作为( 的M机制 )的辅助输入(auxiliary input)
For a given mechanism M, we define the moment αM(λ;aux,d,d′) as the log of the moment generating function evaluated at the value λ
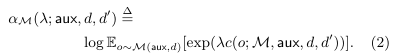
define:
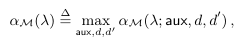
the maximum is taken over all possible aux and all the neighboring databases d, d′
Properties of α
Theorem2.

- 对先前机制输出进行选择
计算,或者去界定每一步的 ,并求和以限制整个机制的 moments
Use the tail bound to convert the moments bound to the (ε,δ)-differential privacy guarantee
The main challenge that remains is to bound the value for each step
Let denote the probability density function(pdf) of , and μ1 denote the pdf of . Let μ be the mixture of two Gaussians , Then we need to compute where
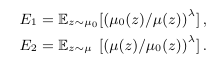
另外,渐进界限
Hyperparameter Tuning
- 与神经网络的结构相比, 模型准确性对训练参数(如批量大小和噪音水平)更敏感
- 批量过大时会增加隐私成本
- differentially private training never reaches a regime where it would be justified
- there is a small benefit to starting with a relatively large learning rate, then linearly decaying it to a smaller value in a few epochs, and keeping it constant afterwards
implementation
- sanitizer,对梯度进行预处理来保护隐私
- privacy-accountant,跟踪训练过程中的隐私开销
Sanitizer.
- 限制每个单独例子的敏感度(Norm clipping)
- 更新网络参数之前对 batch 梯度加噪音
Privacy accountant.
- 计算α(λ):渐进界限(evaluating a closed-form expression)和数值积分
- 选用 numerical integration(数值积分)来计算E1和E2
Differentially private PCA.
捕获输入数据主要特征:
从训练样本中随机抽取样本,将每个向量规范化为 unit norm 来形成矩阵A。给协方差矩阵加高斯噪声,计算出噪音协方差的主要方向。之后对每个输入样本在此方向投影,再将其输入到神经网络中
产生了隐私成本,提升了模型质量,减少了运行时间
Convolutional layers.
略。
DPSGD_Optimizer DP-Train 参考代码
1 | class DPSGD_Optimizer(): |
参考文章
【论文记录】Deep Learning with Differential Privacy
论文阅读:Deep Learning with Differential Privacy